机器人需要一张保姆级地图。
 图片来自网络
图片来自网络
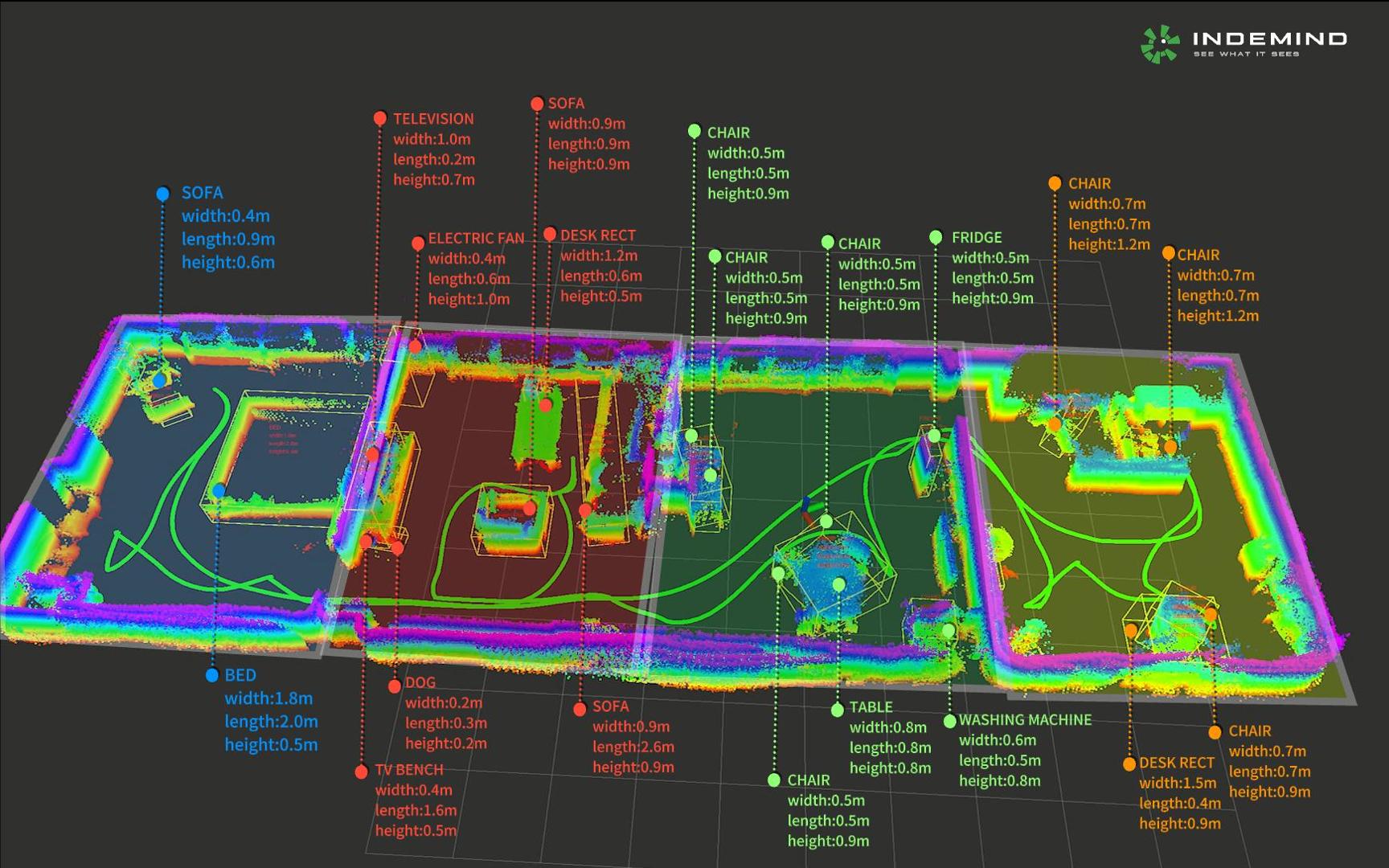
随着机器人的智能化技术不断迭代,对于复杂的行为决策、人机交互等任务仅感知环境的空间几何信息已无法满足要求,它需要让机器人能够像人一样,懂得环境中的物体类别及其位置,即环境的语义信息。以扫地机器人为例,一个清扫餐桌底部的任务便要求它需要知道目标的类别和位置。然而目前主流的传统2D栅格地图、拓扑地图虽然能够描述环境中存在的障碍物几何特征及其环境结构信息,但却缺乏机器人用于理解环境、人机/物机交互等业务逻辑的高层次语义信息,相反,3D语义地图不仅包含物体及环境的结构信息,还有物体类别、功能属性等“常识”性信息,可以说是机器人的保姆级地图。
从技术角度而言,3D语义地图的地图模型是针对真实场景的三维环境重构,包含区域性场景信息及场景中每个独立物体的属性、空间中的三维模型、位姿信息等,使机器人在语义层次上理解环境信息,模仿人类大脑对环境理解的方式,从而为实现更高层次的智能化操作提供信息支持。
要构建3D语义地图,前提是需要提取出你所需要的物体特征,并进行语义切割。INDEMIND在实现构建3D语义地图中,采用了立体视觉技术路线,通过对双目视觉传感器获取到3D视觉点云信息进行点云聚类,并结合边缘端的嵌入式深度学习和VSLAM算法,输出个体性物体语义和区域性场景语义,从而实现3D语义地图构建。
在真实场景中,无论是家庭、公司还是超市,大多拥有着3个及3个以上的细分场景,且这些场景大多有着相似性,当机器人收到指定房间作业任务后如何快速准确地理解房间的功能属性,找到对应房间,并能根据不同房间的功能属性进行个性化作业还需要极高的场景理解准确度。
因此,INDEMIND是根据输出的区域性场景语义和个体性物体语义二者融合的方式实现场景理解。首先,根据获取到的区域性场景语义信息,进行整体特征识别;其次,会根据个体性物体语义识别,对场景中一系列独立个体信息进行识别,并作为场景特征标志,最终通过二相叠加判断,实现准确稳定地场景理解。
在实际表现中,应用3D语义地图的机器人,结合INDEMIND VSLAM算法和智能决策引擎,在AI识别、智能避障、指令智能作业、人机/物机交互等方面均有优异表现。
在AI识别和避障方面,基于3D语义地图,能够快速提取环境中各类图像特征,结合深度学习可立体识别行人、动物、固定/移动物体等个体性障碍物,以及楼梯、自动扶梯等危险场景,避免危险情况发生,这种结合物体3D信息的识别和避障效果的稳定性、准确率都得到显著提升。同时,通过识别到与显示匹配的障碍物3D信息,机器人还可做出类似人类规避动作的精细化操作,能够让机器人有预判、有策略的实现主动避障。
 障碍物检测示意
障碍物检测示意
在交互和智能作业方面,3D语义地图通过对场景中独立个体、房间信息做语义识别及物体分割,机器人懂得人类“常识”后,便能实现高层次的交互逻辑,配合INDEMIND自研的自然语言交互技术,可通过语音、手势、动作等指令,命令机器人进行安全、搜寻、跟随、自主寻路、定向清扫等多种智能作业逻辑。以定向清扫为例,发布语音命令:“清扫一下卧室”可被识别为针对地图上识别到的卧室区域进行一次规划清扫,告别粗糙的交互体验。
目前,3D语义地图技术已应用到INDMEIND推出的家用机器人导航方案「家用机器人AI Kit」和商用机器人导航方案「商用机器人AI Kit」中,两种方案的市场表现均得到了客户的广泛认可。
值得一提的是,两种方案由于采用视觉技术路线,在成本方面相对于竞品均有着明显优势。「家用机器人AI Kit」在实现同等水平的技术效果的同时,成本只有激光雷达融合方案的1/3,且激光视觉融合方案虽然也能获取到场景中的语义信息,但受限于传感器限制,事实上只能识别到物体的二维信息,无法构建3D语义地图。「商用机器人AI Kit」相比激光雷达方案,成本下降了60-80%,机器人开发成本最低可以下探到2千元以内,包含导航和电池的完整底盘成本则可以下探到5千元以内,显著降低机器人的开发成本和周期。